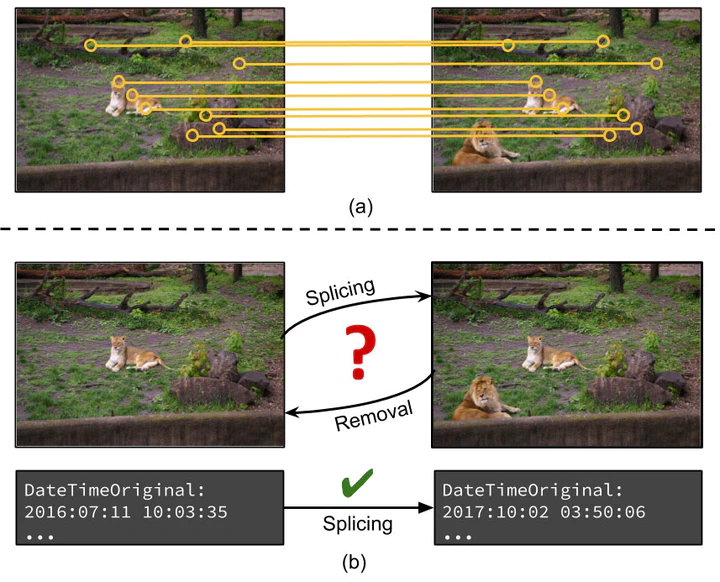
Abstract
Creative works, whether paintings or memes, follow unique journeys that result in their final form. Understanding these journeys, a process known as “provenance analysis”, provides rich insights into the use, motivation, and authenticity underlying any given work. The application of this type of study to the expanse of unregulated content on the Internet is what we consider in this paper. Provenance analysis provides a snapshot of the chronology and validity of content as it is uploaded, re-uploaded, and modified over time. Although still in its infancy, automated provenance analysis for online multimedia is already being applied to different types of content. Most current works seek to build provenance graphs based on the shared content between images or videos. This can be a computationally expensive task, especially when considering the vast influx of content that the Internet sees every day. Utilizing non-content-based information, such as timestamps, geotags, and camera IDs can help provide important insights into the path a particular image or video has traveled during its time on the Internet without large computational overhead. This paper tests the scope and applicability of metadata-based inferences for provenance graph construction in two different scenarios: digital image forensics and cultural analytics.