Abstract
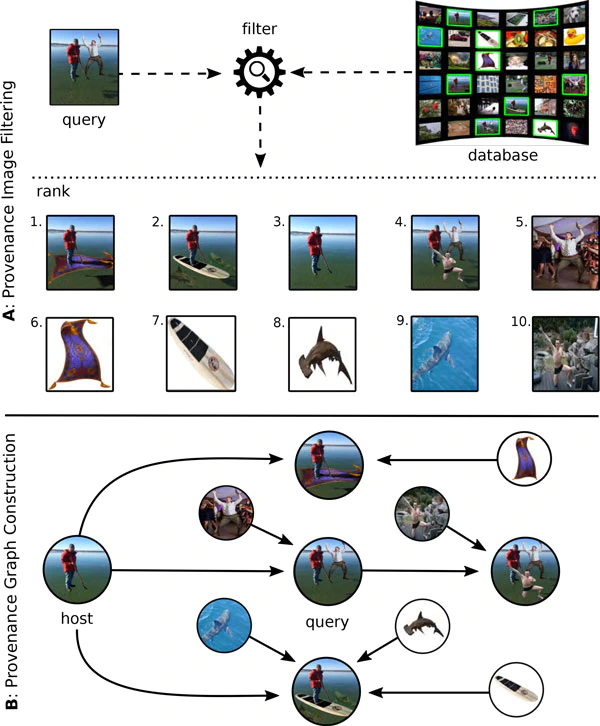
Prior art has shown it is possible to estimate, through image processing and computer vision techniques, the types and parameters of transformations that have been applied to the content of individual images to obtain new images. Given a large corpus of images and a query image, an interesting further step is to retrieve the set of original images whose content is present in the query image, as well as the detailed sequences of transformations that yield the query image, given the original images. This is a problem that recently has received the name of image provenance analysis. In these times of public media manipulation (e.g., fake news and meme sharing), obtaining the history of image transformations is relevant for fact checking and authorship verification, among many other applications. This paper presents an end-to-end processing pipeline for image provenance analysis which works at real-world scale. It employs a cutting-edge image filtering solution that is custom-tailored for the problem at hand, as well as novel techniques for obtaining the provenance graph that expresses how the images, as nodes, are ancestrally connected. A comprehensive set of experiments for each stage of the pipeline is provided, comparing the proposed solution with the state-of-the-art results, employing previously published data sets. In addition, this paper introduces a new data set of real-world provenance cases from the social media site Reddit, along with baseline results.