Abstract
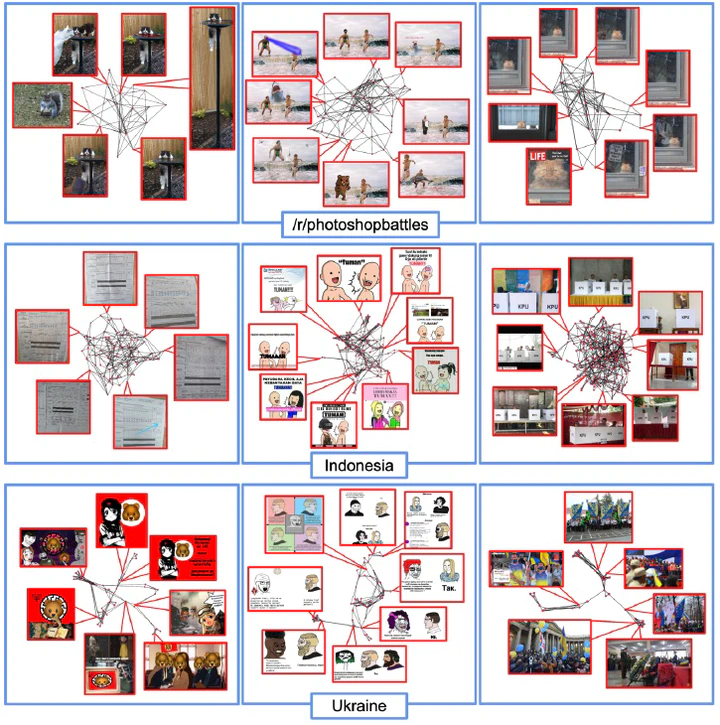
On the internet, images are no longer static; they have become dynamic content. Thanks to the availability of smartphones with cameras and easy-to-use editing software, images can be remixed (i.e., redacted, edited, and recombined with other content) on-the-fly and with a worldwide audience that can repeat the process. From digital art to memes, the evolution of images through time is now an important topic of study for digital humanists, social scientists, and media forensics specialists. However, because typical data sets in computer vision are composed of static content, the development of automated algorithms to analyze remixed content has been limited. In this paper, we introduce the idea of Motif Mining – the process of finding and summarizing remixed image content in large collections of unlabeled and unsorted data. In this paper, this idea is formalized and a reference implementation is introduced. Experiments are conducted on three meme-style data sets, including a newly collected set associated with the information war in the Russo-Ukrainian conflict. The proposed motif mining approach is able to identify related remixed content that, when compared to similar approaches, more closely aligns with the preferences and expectations of human observers.