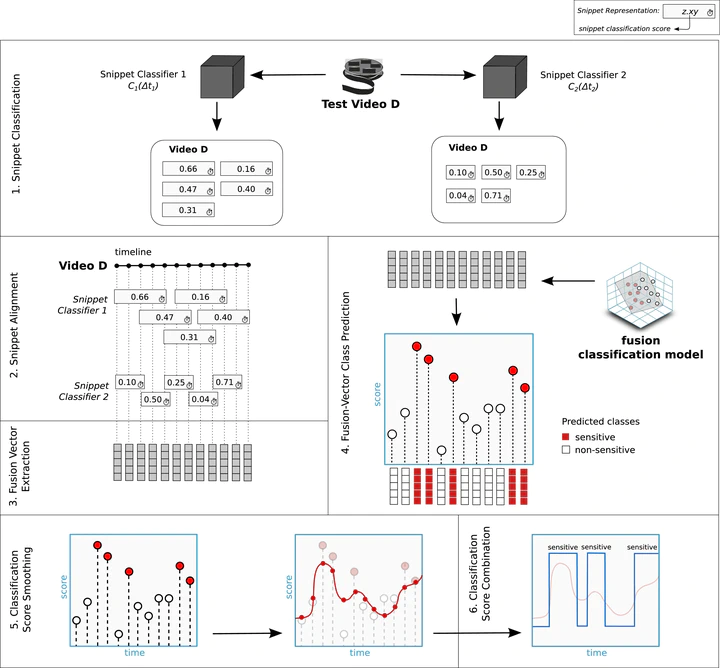
Abstract
The very idea of hiring humans to avoid the indiscriminate spread of inappropriate sensitive content online (e.g., child pornography and violence) is daunting. The inherent data deluge and the tediousness of the task call for more adequate approaches, and set the stage for computer-aided methods. If running in the background, such methods could readily cut the stream flow at the very moment of inadequate content exhibition, being invaluable for protecting unwary spectators. Except for the particular case of violence detection, related work to sensitive video analysis has mostly focused on deciding whether or not a given stream is sensitive, leaving the localization task largely untapped. Identifying when a stream starts and ceases to display inappropriate content is key for live streams and video on demand. In this work, we propose a novel multimodal fusion approach to sensitive scene localization. The solution can be applied to diverse types of sensitive content, without the need for step modifications (general purpose). We leverage the multimodality data nature of videos (e.g., still frames, video space-time, audio stream, etc.) to effectively single out frames of interest. To validate the solution, we perform localization experiments on pornographic and violent video streams, two of the commonest types of sensitive content, and report quantitative and qualitative results. The results show, for instance, that the proposed method only misses about five minutes in every hour of streamed pornographic content. Finally, for the particular task of pornography localization, we also introduce the first frame-level annotated pornographic video dataset to date, which comprises 140 h of video, freely available for downloading.